Die genaue Definition und Abgrenzung von DevOps ist eine sehr schwierige Frage, oft sogar für Fachleute, die schon die Hälfte ihrer beruflichen Laufbahn in diesem Bereich tätig sind. In diesem kurzen Artikel werden wir versuchen zu erklären, was diese Rolle beinhaltet und was sie zu vermeiden versucht. Der Schwerpunkt liegt auf Entwicklern, Systemadministratoren und Einsatzadministratoren (Betrieb).
 In den Anfängen der Technologieentwicklung bestand das Projektteam, das die Anwendungen erstellte, aus Entwicklern, Analytikern, Testern, Systemadministratoren, Netzwerkern und Hardwarespezialisten. Wenn dieses Team zusammen war, war es schon die halbe Miete. Sehr vereinfacht: Die für die Entwicklung zuständigen Personen erstellten die Anwendung (Entwickler) und übergaben sie an Systemadministratoren, die sie (wie auch immer automatisiert) auf der Hardware im Serverraum installierten.
In den Anfängen der Technologieentwicklung bestand das Projektteam, das die Anwendungen erstellte, aus Entwicklern, Analytikern, Testern, Systemadministratoren, Netzwerkern und Hardwarespezialisten. Wenn dieses Team zusammen war, war es schon die halbe Miete. Sehr vereinfacht: Die für die Entwicklung zuständigen Personen erstellten die Anwendung (Entwickler) und übergaben sie an Systemadministratoren, die sie (wie auch immer automatisiert) auf der Hardware im Serverraum installierten.
Vor nicht allzu langer Zeit kam der so genannte agile Entwicklungsansatz ins Spiel. Dadurch wurde die Kommunikation zwischen Entwicklern und Betreibern zunehmend komplexer. Im Grunde genügte wenig, um sicherzustellen, dass das Produkt (oder eine Version davon), auf das der Kunde ungeduldig wartete, überhaupt nicht geliefert wurde. Das Produkt, oder eine Version davon, wurde schließlich geliefert, aber mit erheblichen Fehlern. Schuld daran war und ist vor allem die Kommunikation zwischen den verschiedenen Teilen des Teams.
Es gibt also Entwickler und Betreiber. Diese beiden Lager können versuchen, miteinander zu kommunizieren und zu argumentieren, aber in der Praxis ist das sehr schwierig. Jeder spricht sozusagen seine eigene Sprache oder einen anderen Dialekt. Was aus Sicht der Entwicklung einfach ist, kann aus Sicht der Infrastruktur nicht auf Servern implementiert werden. Und was in der Infrastruktur sehr einfach zu lösen ist, wird für Entwickler eine sehr schwierige Aufgabe sein.
Was würde passieren, wenn wir einen Entwickler hätten und ihn zum Studieren zu den Betreibern schicken würden? Oder haben sie jemanden aus dem operativen Geschäft zu den Entwicklern geschickt, um sie herauszufordern? Dieser Schritt wird schließlich jemanden hervorbringen, der sich als DevOps-Spezialist bezeichnen kann. Aber um diesen Titel wirklich zu „verdienen“, müssen sie mehr als nur verstehen, woraus das Projekt besteht und wo es implementiert wird. Sie müssen vor allem ihre Denkweise ändern.
Es geht um eine ganze Reihe von Praktiken, die die Prozesse zwischen Softwareentwicklung und Betrieb automatisieren und standardisieren, damit Software schneller und zuverlässiger erstellt, getestet und freigegeben werden kann.
Neue Denkweise + neue Tools + neue Fertigkeiten = DevOps
You build it, you run it!
Die Grundidee ist, dass DevOps nicht nur eine Technologie ist, sondern ein ganzes Entwicklungsparadigma. Damit dies in einem Unternehmen funktioniert, müssen nicht nur die verwendeten Anwendungen geändert werden, sondern auch die gesamte Herangehensweise an die Entwicklung, das Testen und den Einsatz in der Produktion sowie das gesamte Denken über den Prozess.
Früher wäre dies utopisch gewesen, aber heute ist es möglich, ganze Cluster mit Verbindungen zu verschiedenen Diensten zu mieten und zu verwalten, von Datenbanken (z. B. PostgreSQL, MySQL oder CockroachDB), Warteschlangen (wie Kafka oder RabbitMQ), Analysesystemen (Hadoop), Logging- und Überwachungsinfrastruktur (Elasticsearch, Kibana, Grafana) bis hin zu verschiedenen IoT-Diensten und REST-APIs. Und wie könnte man den gesamten Prozess von der Erstellung bis zur Bereitstellung beschleunigen, wenn man diese Anwendungen nicht selbst ausführen kann?
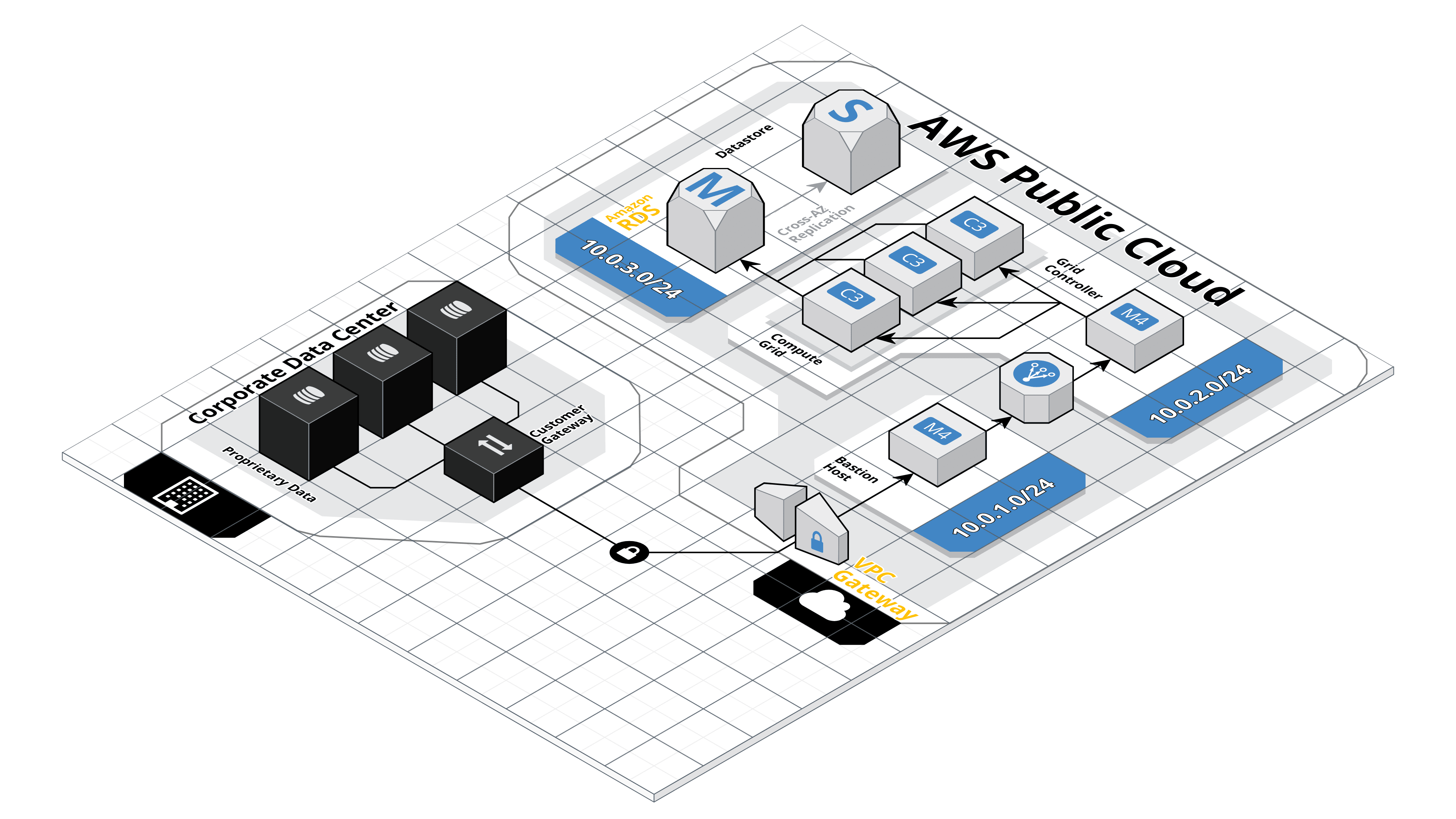
Hybrid Cloud Architecture
Virtual Private Cloud
Wenn ein Unternehmen eine Anwendung betreibt, geht der Trend heute dahin, die Cloud anstelle der eigenen On-Premise-Infrastruktur zu nutzen. Cloud-Infrastrukturen können heute schon auf hohe Verfügbarkeit und niedrige Latenzzeiten optimiert werden, sie können sogar so eingerichtet werden, dass z.B. Kunden aus Tschechien die Datenwolke in Deutschland nutzen und Kunden aus Frankreich in Frankreich. Moderne Clouds erfüllen hohe Sicherheitsstandards, und ein weiterer Vorteil ist die Möglichkeit, viele der mit ihrem Betrieb verbundenen Technologien als Service zu nutzen. In der Praxis bedeutet dies, dass die Unternehmen keine Spezialisten für die Infrastruktur, deren Wartung und Installation beschäftigen müssen, da sie all dies als Service erhalten, in dem sie ihre Anwendungen in Form von Microservices ausführen. Dies spart sowohl (heutzutage knappe) Arbeitskräfte als auch Geld. Es ist wichtig, neue Anwendungen als Cloud Native zu entwickeln. Die gängigsten Clouds sind Azure, AWS und Google Cloud.
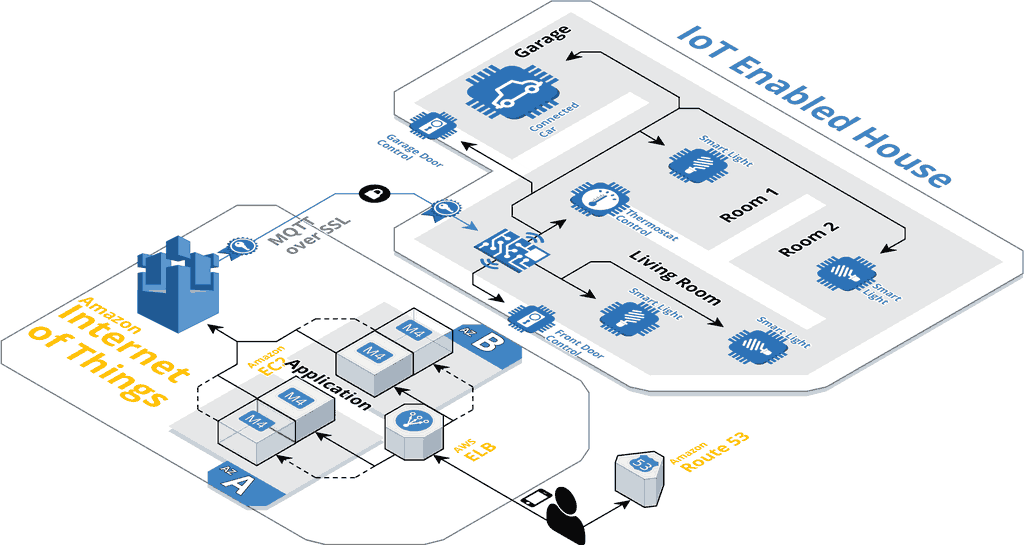
Internet of Things Architecture
Microservice-Architektur
Früher wurden die meisten Anwendungen als monolithische Systeme entwickelt. Heutzutage bestehen die Anwendungen aus kleineren Teilen, die über eine einzige Schnittstelle miteinander kommunizieren. Der Vorteil? Die monolithischen Anwendungen brauchen eine Viertelstunde, um zu starten, während kleinere Anwendungen nur wenige Sekunden benötigen. Bei Microservice-Architekturen versuchen wir immer, sie als Platform as a Service oder Software as a Service einzusetzen.
Eine beliebte Methode in diesem Bereich ist die „Zwölf-Faktoren-App“, bei der es sich um eine Reihe von Regeln handelt, die die Entwicklung viel transparenter machen, wenn sie vom gesamten Team befolgt werden. Es wird beschrieben, wie man mit dem Code umgeht, wo man Konfigurationen speichert, was man mit Backups und Builds macht, wie man skaliert, Protokolle erstellt oder verwaltet.
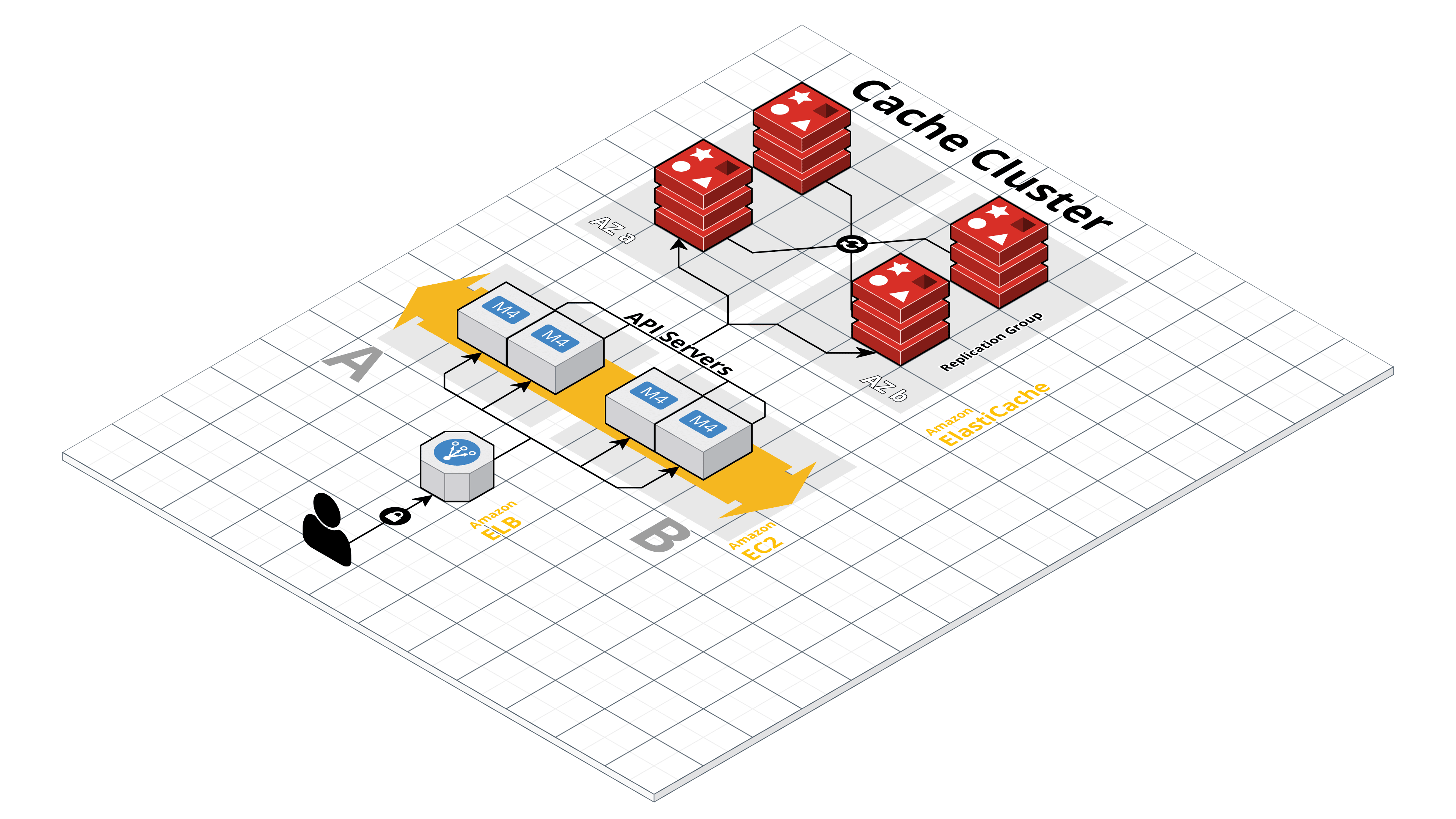
Caching Cluster Architecture
Serverlose Architektur
Ein weiterer sehr interessanter Baustein der modernen Anwendungsarchitektur ist „serverless“. Von den oben erwähnten kleinen Anwendungen nehmen wir einfach einen Teil des Codes, der rechenintensiv sein könnte, oder im Gegenteil, es ist nicht notwendig, ihn ständig laufen zu lassen, und verwenden eine Schnittstelle, die sowohl AWS (AWS Lambda) als auch Azure (Azure Functions) offenlegt, die kleine Unterprozesse startet, die Ergebnisse berechnet und sie an den Dienst zurückgibt. Es kann sogar auf der Ebene von Funktionen skaliert werden, die parallel und unabhängig voneinander laufen können.
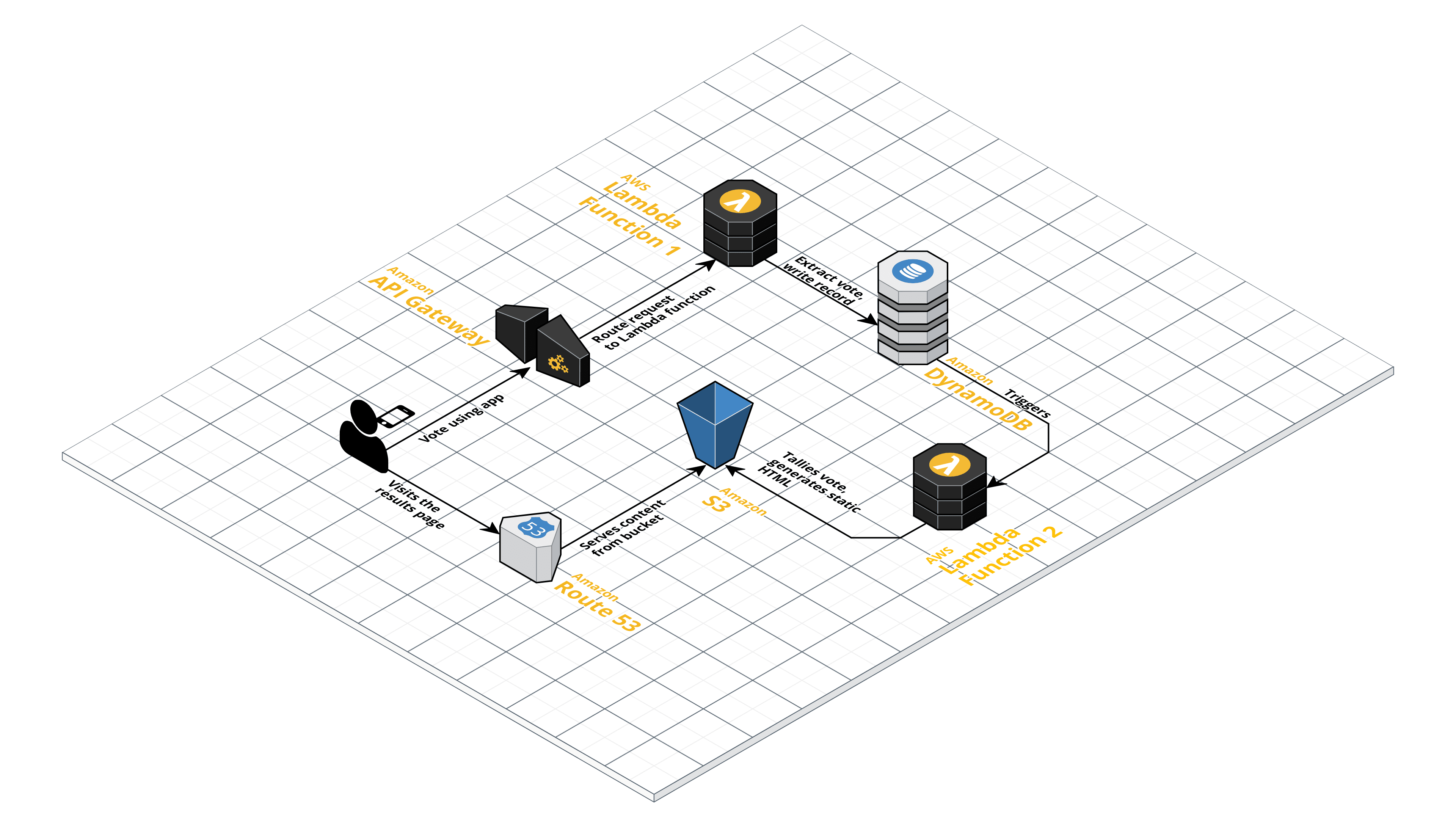
Serverless Application Architecture
Automatisierung
Eine weitere Eigenschaft, die für DevOps geeignet ist, haben wir noch nicht erwähnt: die Faulheit. DevOps versucht, das Leben durch Automatisierung so einfach wie möglich zu machen. Und die Automatisierung ist das A und O der heutigen DevOps-Entwicklung. Wir automatisieren die Bereitstellung, die Arbeitsabläufe, die Tests, die Infrastruktur und die Verwaltung und Überprüfung der Benutzerrechte und des Zugriffs - einfach alles. Wann sollte man mit der Automatisierung beginnen? Wenn eine Aktivität mehr als einmal wiederholt werden muss.
Automatisierte Codeprüfung
Um schnell entwickeln zu können und sicherzustellen, dass wir nichts kaputt gemacht haben, müssen wir alles durch Tests abdecken, die die Entwickler selbst schreiben. Dieser Gedanke wird ad absurdum geführt und bedeutet, dass zuerst der Test und dann die Funktion programmiert werden sollte. Test Driven Development ist keine Neuheit in der Softwareentwicklung. Nicht auf Tester zu warten und eigene Tests zu schreiben, ist Teil des oben erwähnten DevOps-Denkens.
In der Java-Welt verwenden wir zu diesem Zweck JUnit, Mockito, MockMvc, Selenium, Sonar, usw.. Es gibt also genügend Werkzeuge, oft fehlt es aber an der Bereitschaft der Entwickler, dies zu tun.
Automatisierung von Arbeitsabläufen
Wir verwenden Tools wie Jenkins (CI/CD), GitLab, Container Registry, Jira, um Arbeitsabläufe zu automatisieren. In der Praxis sieht es so aus, dass der Entwickler seinen Code in GitLab einstellt, die automatisierte Pipeline darauf Unit-Tests durchführt, das Programm kompiliert und es in die Umgebung auf dem Server einstellt, wo es dann kontinuierlich überwacht wird. Im Idealfall läuft wirklich alles von selbst.
Automatisierung der Infrastruktur: Infrastruktur als Code!
Der ideale Endzustand ist, dass in allen Umgebungen immer alles gleich läuft und dass diese Umgebungen mit einem Klick erstellt werden. So installiert jedoch niemand das Betriebssystem, sondern alles soll über verschiedene Vorlagen in einem Skript erfolgen. Um Infrastruktur als Code zu erstellen, müssen wir zunächst die Anwendung von der Hardware entkoppeln. Tools wie Docker und Podman übernehmen diese Aufgabe. Wir nehmen die von uns erstellte Anwendung und stellen sie in einem Ökosystem bereit - in der Regel Kubernetes oder OpenShift. Alles kann vor Ort ausgeführt werden, aber das ist nicht das, worum es bei DevOps geht. Sowohl Kubernetes als auch OpenShift können mit wenigen Klicks ausgeführt werden. Kubernetes läuft gehostet bei allen großen Anbietern (AWS EKS, Azure AKS oder Google GKE).
Für die Infrastruktur haben wir mehrere Möglichkeiten. Wir können die Infrastruktur bequem von einem Webbrowser aus „anklicken“ oder, und das ist vorzuziehen, eine Vorlage für den Anbieter erstellen, um die Infrastruktur direkt über die API-Ebene aufzubauen.
Die am häufigsten verwendete universelle Vorlagensoftware ist Terraform. Sie enthält Verbindungen zu allen wichtigen Providern, aber auch die Nutzung von Servern vor Ort ist möglich. Einfacher und oft besser ist es, diese Vorlagen in nativen Skripten zu schreiben (für AWS z. B. CloudFormation in YAML und JSON, oder neuerdings AWS CDK, wo es möglich ist, die Infrastruktur z. B. in JavaScript, JAVA oder Python zu beschreiben). Dadurch werden die Möglichkeiten des Anbieters optimal genutzt. Diese Vorlage kann verwendet werden, um identische Umgebungen mehrmals hintereinander zu erstellen (geeignet für verschiedene Entwicklungs-/Testumgebungen). Die Anwendungen selbst können mit allen bekannten Tools von Jenkins, Gitlab, Bitbucket in die Umgebung übertragen werden.
Messungen
Wir haben die Anwendung in Betrieb, aber das ist noch nicht alles. Wir müssen damit beginnen, sie zu bewerten, zu analysieren und Fehler zu korrigieren, also brauchen wir kontinuierliche Metriken und Analysewerkzeuge. Um Protokolle zu sammeln und zu visualisieren, können Sie ELK Stack verwenden, was ein ganzes Paket von Tools für diesen Zweck ist. Kibana ist ein Werkzeug, mit dem Sie Protokolle in einer visualisierten Form an einem Ort durchsuchen können, was es Ihnen ermöglicht, die Leistung der Anwendung herauszufinden und möglicherweise herauszufinden, wo genau das Problem liegt, zusätzlich zur Fehlerfilterung können Sie auch Metriken der CPU usw. anzeigen.
Methodik
Der früher beliebte und häufig verwendete Wasserfallansatz ermöglicht eine sorgfältige, aber keineswegs schnelle Entwicklung. Aus diesem Grund werden heute die viel diskutierten agilen Methoden eingesetzt, die es ermöglichen, die Entwicklung in kleine Teile zu zerlegen und stückweise auszuführen. Wenn man darüber nachdenkt, ist dies im Grunde die Essenz der gesamten DevOps-Philosophie - von der Infrastruktur bis zur Methodik und andersherum. So praktizieren wir tägliche Stand-Ups und Entwicklungsläufe in kurzen Sprints. Es ist wichtig, den gesamten Entwicklungsprozess zu standardisieren, angefangen bei der Analyse über die Entwicklung, das Testen, die Bereitstellung und die Überwachung der Leistung der fertigen Anwendung.
Schlussfolgerung
Damit ein DevOps-Projekt erfolgreich ist, bedarf es einer Kombination aus Fachwissen, hochwertiger Technologie, handwerklichem Geschick und vor allem einer Veränderung in der Arbeitsweise des Teams und der Denkweise der Entwickler. Aber dann ist es das wert. Ein gut konfiguriertes Projekt ermöglicht schnellere Innovationen, ist in der Lage, auf geschäftliche Anforderungen zu reagieren, die Zusammenarbeit im Team ist effizienter, die allgemeine Codequalität steigt und führt zu häufigeren Veröffentlichungen.
Source: SystemOnLine